
Tutorial: Build a RAI Model#
This tutorial guides you through the process of creating a model of retail business sales, using a portion of the sample TPC-DS dataset available in Snowflake.
You’ll learn how to:
- Create a model with entities derived from Snowflake tables.
- Use graph reasoning to extend the model with new entities and relationships.
- Visualize the model as a graph.
- Export data from the model to a Snowflake table.
Table of Contents#
- Set Up Your Environment
- Configure Your Snowflake Connection
- Get the Sample Data
- Model the Data
- Extend the Model
- Detect Customer Segments with Graph Reasoning
- Explore the Differences Between Customer Segments
- Export Segment Data to Snowflake
- Summary and Next Steps
Set Up Your Environment#
This tutorial is designed to be run in a local Python notebook, like Jupyter Lab, or in a cloud-based notebook environment like Snowflake or Google Colab. For instructions on setting up a cloud-based notebook, see Getting Started: Cloud Notebooks.
For a local Python environment, you’ll need to install the relationalai, jupyter, and matplotlib packages:
## Activate your Python virtual environment.
source .venv/bin/activate
# Install the relationalai and jupyter packages.
python -m pip install relationalai jupyter matplotlib
See Getting Started: Local Python for full Python setup instructions.
Once the packages finish installing, start a Jupyter server with the following command:
#jupyter lab
A new browser window will open with the Jupyter Lab interface. Create a new Python 3 notebook and follow along with the tutorial by copying and pasting the code snippets into the notebook cells.
Configure Your Snowflake Connection#
RAI models require a connection to a Snowflake account where the RAI Native App is installed.
You can configure your connection using the save_config() function:
#import relationalai as rai
rai.save_config("""
account = "<SNOWFLAKE_ACCOUNT_ID>"
user = "<SNOWFLAKE_USER>"
password = "<SNOWFLAKE_PASSWORD>"
role = "<SNOWFLAKE_ROLE>"
warehouse = "<SNOWFLAKE_WAREHOUSE>"
""")
Replace the placeholders with your Snowflake account details:
| Placeholder | Description |
|---|---|
<SNOWFLAKE_ACCOUNT_ID> | Your Snowflake account’s unique identifier. Refer to Snowflake Account Identifiers for details. |
<SNOWFLAKE_USER> | Your Snowflake username. |
<SNOWFLAKE_PASSWORD> | Your Snowflake password. |
<SNOWFLAKE_ROLE> | The role you want to use for the connection. Must have the necessary application roles to interact with the RAI Native App. |
<SNOWFLAKE_WAREHOUSE> | The Snowflake warehouse you want to use for the connection. |
Snowflake credentials are hardcoded in this example for simplicity.
In Part Two of this tutorial, you’ll learn how to manage credentials securely using a raiconfig.toml file.
Get the Sample Data#
We’ll use the TPC-DS benchmark dataset available in Snowflake as our source data. The TPC-DS dataset contains a set of tables that represent a retail business and its operations. For this tutorial, we’ll use two tables and a subset of their columns:
| Table Name | Description | Columns Used |
|---|---|---|
SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.STORE_SALES | Sales data for a retail store |
|
SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.ITEM | Item data for products sold in the store |
|
The SNOWFLAKE_SAMPLE_DATA database is available by default in newer Snowflake accounts.
See the Snowflake documentation for details on creating this database if it does not exist in your account.
The TPCDS_SF10TCL schema contains a subset of the TPC-DS tables with 10 terabytes of scale factor.
We’ll filter this data further to focus on a single store and a single year of sales data.
Execute the following to create a new RAI_TUTORIAL.TPCDS schema and populate it with sample data from the STORE_SALES and ITEM tables in the SAMPLE_SNOWFLAKE_DATA database:
## Create a Provider instance for executing SQL queries and RAI Native App commands.
provider = rai.Provider()
# Change the following if necessary to the name of the database where the
# sample data is stored in your Snowflake account.
SAMPLE_DATA_DB = "SNOWFLAKE_SAMPLE_DATA"
# Change the following if you want to use a different database and schema name
# for the tutorial data.
TUTORIAL_SCHEMA = "RAI_TUTORIAL.TPCDS"
# Do not change anything below this.
TUTORIAL_DB = TUTORIAL_SCHEMA.split(".")[0]
provider.sql(f"""
BEGIN
CREATE DATABASE IF NOT EXISTS {TUTORIAL_DB};
CREATE SCHEMA IF NOT EXISTS {TUTORIAL_SCHEMA};
-- Create a sample store_sales table with data for a single store
-- between 2001-01-01 and 2001-12-31.
CREATE TABLE IF NOT EXISTS {TUTORIAL_SCHEMA}.STORE_SALES AS
WITH date_dim AS (
SELECT *
FROM {SAMPLE_DATA_DB}.TPCDS_SF10TCL.DATE_DIM
WHERE d_date BETWEEN '2001-01-01' AND '2001-12-31'
),
store AS (
SELECT *
FROM {SAMPLE_DATA_DB}.TPCDS_SF10TCL.STORE
LIMIT 1
)
SELECT ss_customer_sk, ss_item_sk
FROM {SAMPLE_DATA_DB}.TPCDS_SF10TCL.STORE_SALES ss
JOIN date_dim dd ON ss.ss_sold_date_sk = dd.d_date_sk
JOIN store st ON ss.ss_store_sk = st.s_store_sk;
ALTER TABLE {TUTORIAL_SCHEMA}.STORE_SALES SET CHANGE_TRACKING = TRUE;
-- Create a sample item table with items from the filtered STORE_SALES table.
CREATE TABLE IF NOT EXISTS {TUTORIAL_SCHEMA}.ITEM AS
SELECT i_item_sk, i_category, i_class
FROM {SAMPLE_DATA_DB}.TPCDS_SF10TCL.ITEM i
JOIN {TUTORIAL_SCHEMA}.STORE_SALES ss ON i.i_item_sk = ss.ss_item_sk;
ALTER TABLE {TUTORIAL_SCHEMA}.item SET CHANGE_TRACKING = TRUE;
END;
""")
Model the Data#
Now that we have our source data, we can build a RAI model on top of it. In a new cell, create a model named “RetailStore”:
## Create a RAI model named "RetailStore."
model = rai.Model("RetailStore")
You may see a message indicating that an engine is being created or resumed for you. Engines are RAI Native App compute resources similar to Snowflake warehouses. They are used to evaluate queries from RAI models.
You may change which engine is used or created by setting the engine configuration key to the name of your engine in the save_config() function used to configure your Snowflake connection.
Engines are created and resumed asynchronously, and may take several minutes to become available. You can continue to define your model while the engine is being provisioned.
There are two basic building blocks of a RAI model:
-
Types represent sets of entities with similar properties. They can model any logical grouping, including:
- Physical entities, like
Store,Item, orCustomer - Business concepts, like
Sale,Order, orMarketingCampaign - States, like
OnSaleorDiscontinued
- Physical entities, like
-
Rules define properties of and relationships between entities. They can model things like:
- Business logic, like how to calculate a customer’s lifetime value.
- Expert knowledge, like how to classify a customer as a potential churn risk.
- Data transformations, like how to normalize a customer’s address.
Execute the following to define Sale and Item types from the sample STORE_SALES and ITEM tables and create rules that set properties for the entities in those types:
## Define types from the STORE_SALES and ITEM tables.
Sale = model.Type("Sale", source=f"{TUTORIAL_SCHEMA}.STORE_SALES")
Item = model.Type("Item", source=f"{TUTORIAL_SCHEMA}.ITEM")
# Define rules to alias the columns names from the source tables with more
# natural names. Note that this does not modify the source tables.
with model.rule():
item = Item()
item.set(
item_id=item.i_item_sk,
category_name=item.i_category,
class_name=item.i_class
)
with model.rule():
sale = Sale()
sale.set(
item_id=sale.ss_item_sk,
customer_id=sale.ss_customer_sk
)
# Define an item property on Sale entities that joins them to Item entities by
# matching a sale's item_id property to an item's item_id property.
Sale.define(item=(Item, "item_id", "item_id"))
We’ll break down these rules in a moment. First, run the following in a new cell to query the model for the first five sales entities and their customer and item IDs:
#from relationalai.std import aggregates
# Get five sales entities and their customer and item IDs.
with model.query() as select:
sale = Sale()
# Limit to the first 5 sales entities.
aggregates.bottom(5, sale)
response = select(
sale, # Select sale entities.
sale.customer_id, # Select the customer_id property.
sale.item.item_id # Select the item_id property of the related item entity.
)
# Query results are stored in response.results as a pandas DataFrame. Note the
# column names. The column for sale entities indicates that those entities are
# from the store_sales table in Snowflake. The values in that column are the
# internal model IDs of the entities.
response.results
# sf_store_sales customer_id item_id
# 0 3dWa1/81JwZssVkYhgUAAA 32236060 47875
# 1 LU8RjOP4+t0kS4MFTxAAAA 27653516 327615
# 2 RXfpME/xII4k+YOC/gsAAA 49912548 374833
# 3 i2zIw1QHQE7/72M+vAMAAA 34713100 300013
# 4 okXnvnm3AJOMSB/L9BAAAA 43835155 127789
The first time you query a model, the RAI Native App must prepare the model’s data. This process takes several minutes but only happens once. Subsequent queries will be faster. See Data Management for more information on how data for RAI models are managed.
Note that if your engine is not yet available, the query will block until the engine is ready.
When you create a type using the model.Type() method, the optional source parameter specifies the Snowflake table from which the set of entities in the type is derived.
Properties are automatically created from the columns in the source tables.
Not all column types are supported in source tables and views. See Defining Objects From Rows In Snowflake Tables for details.
Types are flexible:
- Entities may belong to multiple types.
- Entities in the same type may have different properties.
In the example above, two non-overlapping types, Sale and Item, are defined from the STORE_SALES and ITEM tables, respectively.
Although types represent collections of entities, the entities aren’t created until the model is queried.
In particular, Type objects aren’t Python collections and cannot be iterated over.
Instead of looping through entities, rules use RAI’s declarative query-builder syntax to dynamically create entities and assign their types and properties.
You create a rule with model.rule(), a context manager that must be used with a with statement.
The rule’s logic is defined in the indented block following the with statement using RAI’s declarative query-builder syntax.
Rules produce effects, such as creating entities or setting properties, based on combinations of entities that meet the rule’s conditions.
Here’s a breakdown of the first rule above that defines properties for Item entities:
| Line | Description |
|---|---|
with model.rule(): | Creates a new rule context. |
item = Item() | Creates an Instance that matches any Item entity. |
item_id = item.i_item_skcategory_name = item.i_categoryclass_name = item.i_class | Creates InstanceProperty objects that match values item has for the i_item_sk, i_category, and i_class columns from the source table. |
item.set(item_id=item_id, ...) | Sets the item_id, category_name, and class_name properties on Item entities to the values of the corresponding columns from the source table. |
Instance and InstanceProperty objects represent placeholders for values that are determined when queries are evaluated, not when they are defined.
When a rule’s with block is executed by Python, the rule is compiled into an intermediate representation and saved in the model object.
Rules are evaluated on-demand when queries are executed, and any changes to source tables and views are reflected in the model. New matches trigger the rule’s effects, and effects are removed when former matches no longer satisfy the rule’s conditions.
Think of rules as instructions for the RAI Native App to follow when evaluating queries from the model. They are evaluated on-demand and do not modify source Snowflake tables in any way.
Like rules, queries are written in a with statement using RAI’s declarative query-builder syntax.
The preceding query works as follows:
| Line | Description |
|---|---|
with model.query() as select: | Creates a new query context. select is a ContextSelect object that can be called to select the query results. |
sale = Sale() | Creates an Instance that matches any Sale entity. |
aggregates.bottom(5, sale) | Limits the sale instance to the first five entities. |
response = select(sale, sale.customer_id, sale.item.item_id) | Selects sale entities, their customer_id property, and the related item’s item_id property. Results are stored in response.results as a pandas DataFrame. |
Queries aren’t evaluated by your local Python process.
When you execute a model.query() block, the query and all of the types and rules in the model are compiled and sent to the RAI Native App for evaluation.
Your Python process is blocked until the query results are returned.
Extend the Model#
There are only two source tables, STORE_SALES and ITEM, in our sample dataset.
But there are more entities in the data that we can model.
For example, each Sale entity has a customer_id property that we can use to define a Customer type:
## Create a Customer type, without a source table.
Customer = model.Type("Customer")
# Define Customer objects from Sale entities using the customer_id property.
with model.rule():
sale = Sale()
customer = Customer.add(customer_id=sale.customer_id)
customer.items_purchased.add(sale.item) # Set a multi-valued property
sale.set(customer=customer)
Here’s the breakdown:
| Line | Description |
|---|---|
sale = Sale() | Creates an Instance that matches all Sale entities. |
customer = Customer.add(customer_id=sale.customer_id) | Uses the Customer.add() method to create new Customer entities with a customer_id property for each unique customer_id of a Sale entity. |
customer.items_purchased.add(sale.item) | Creates a multi-valued property on Customer entities that joins them to Item entities that they have purchased. |
sale.set(customer=customer) | Sets a single-valued property on Sale entities that joins them to their Customer entities. |
Single-valued properties, like sale.customer, represent a one-to-one relationship between an entity and a value.
Multi-valued properties, like customer.items_purchased, represent a one-to-many relationship between an entity and a set of values.
By convention, we give multi-valued properties plural names.
Properties set using Type.add() are single-valued and are used to uniquely identify the entity.
See Defining Objects in Rules and Setting Object Properties for more information.
The TPCDS sample data does have a CUSTOMER table.
In a real-world scenario, you would define a Customer type from the CUSTOMER table and join it to Sale entities using the customer_id property.
However, as this example demonstrates, you can also define types without source tables using rules.
Let’s also define an ItemCategory type from each Item entity’s category_name and class_name properties:
#from relationalai.std import strings
ItemCategory = model.Type("ItemCategory")
with model.rule():
# Get an Instance object that matches any Item entity.
item = Item()
# Concatenate the category_name and class_name properties to create a full category name.
full_name = strings.concat(item.category_name, ": ", item.class_name)
# Create an ItemCategory entity with the full category name.
category = ItemCategory.add(name=full_name)
# Set a multi-valued property on the ItemCategory entity to items in the category.
category.items.add(item)
# Set a single-valued property on Item entities to their related ItemCategory entity.
item.set(category=category)
In this rule, strings.concat() concatenates Item entities’ category_name and class_name values.
The result is used to create an ItemCategory entity with a name property that represents the full category name.
Recall that InstanceProperty objects like item.category_name are placeholders, not actual values.
Operators like +, -, ==, and != are overloaded to work within rules and queries where possible.
Other operations, like string concatenation, require functions from the RAI Standard Library.
Now that you’ve defined the Customer and ItemCategory types, you can query the model to see what percentage of customers have purchased items from each category:
#from relationalai.std import aggregates, alias
# Get the number of sales per item category.
with model.query() as select:
# Get an Instance that matches any Sale entity.
sale = Sale()
# Get an InstanceProperty that matches related Customer entities.
customer = sale.customer
# Get an InstanceProperty that matches related ItemCategory entities.
category = sale.item.category
# Count the total number of customers.
num_customers = aggregates.count(customer)
# Count the number of customers that have purchased an item from each category.
num_customers_per_category = aggregates.count(customer, per=[category])
# Calculate the percentage of customers that have purchased an item from each category.
pct_customers_per_category = num_customers_per_category / num_customers
# Select category names and the percentage of customers per category.
response = select(
category.name,
alias(pct_customers_per_category, "pct_customers") # Change the result column name
)
# Visualize the query results as a bar chart. People primarily buy clothing
# and music at this store.
(
response.results
.set_index("name")
.sort_values("pct_customers", ascending=False)
.head(25) # Only show the top 25 categories
.plot(
kind="bar",
xlabel="Category",
ylabel="Percentage of customers",
title="Percentage of customers per item category",
figsize=(16, 4),
rot=90,
legend=False
)
)
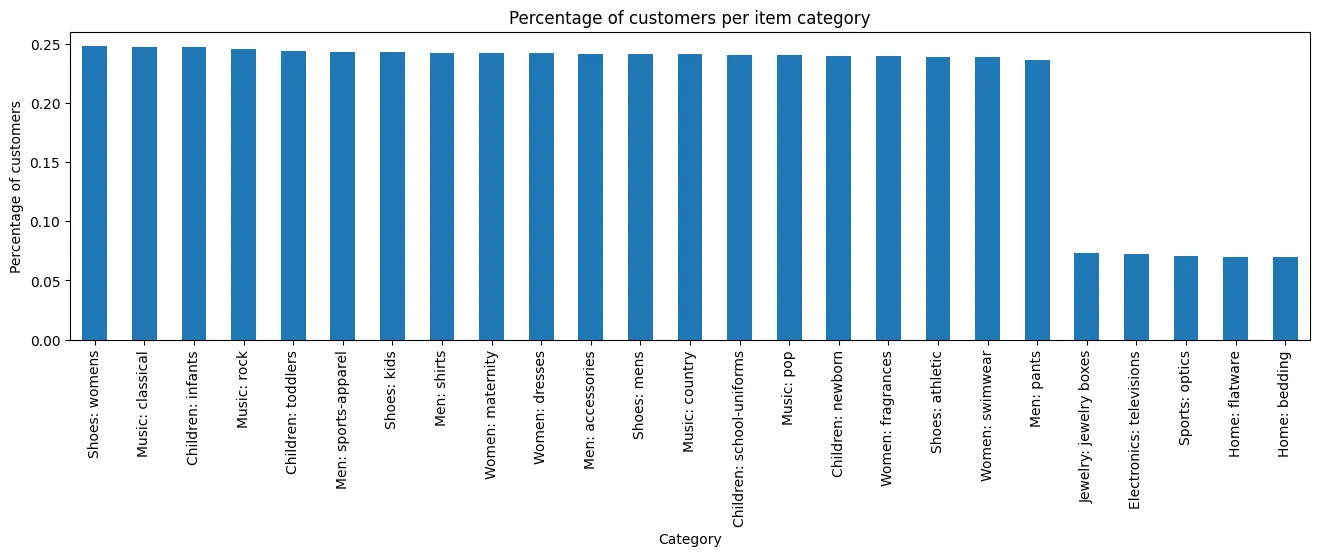
In this query:
aggregates.count()is used to count the total number of customers and the number of customers that bought an item from each category.- The percentage of customers that bought an item from each category is calculated by dividing the number of customers per category by the total number of customers.
alias()is used to change the name of the calculated percentage column in the query results topct_customers.
Python’s built-in aggregation functions, like len(), sum(), and max(), can’t be used to aggregate values produced by RAI Producer objects.
You must use the functions in relationalai.std.aggregates, instead.
See Using Aggregate Functions for more information.
Detect Customer Segments with Graph Reasoning#
Our goal is to find segments of customers that have similar purchasing behavior, so that we can target them with more personalized marketing campaigns. Before we can do that, we need to define a graph.
A graph is a collection of nodes, that represent entities, and edges, which represent relationships between entities.
In our case, we’ll create a graph where each node is a Customer entity and add an edges between two customers if they have purchased the same item.
#from relationalai.std import graphs
# Define a customer graph.
customer_graph = graphs.Graph(model, undirected=True)
# Write a rule that adds an edge between two customers if they've purchased the same
# item. Note that nodes are automatically added to the graph when edges are added.
with model.rule():
# Get a pair of Customer instances.
customer1, customer2 = Customer(), Customer()
# Filter for distinct pairs of customers.
customer1 != customer2
# Filter for customers that have purchased at least one item in common.
customer1.items_purchased == customer2.items_purchased
# Add an edge between the customers in the customer_graph.
customer_graph.Edge.add(customer1, customer2)
Here, we:
- Define an empty
customer_graphobject using theGraphclass from the RAI Standard Library. Theundirected=Trueparameter specifies that edges have no directionality. An edge betweencustomer1andcustomer2is the same as an edge betweencustomer2andcustomer1. - Declare a rule that adds an edge to the graph between two distinct customers if they have purchased at least one item in common.
This rule highlights the declarative nature of RAI’s Python API. You define the conditions under which edges are added to the graph, and the RAI Native App takes care of the rest.
Conditions are created using operators like ==, !=, <, and >.
For example, customer1 < customer2 compares the internal IDs of customer1 and customer2 to ensure that only distinct pairs of customers are considered.
Conditions on separate lines are combined using logical AND, so all conditions must be true for the rule to trigger its effects.
While an InstanceProperty for a multi-valued property, like customer1.items_purchased, matches any value in the set of values that the property can take, it only matches one value at a time.
As a result, the expression customer1.items_purchased == customer2.items_purchased doesn’t filter for customers who have all items in common, but for customers who have at least one item in common.
Expressions like customer1.items_purchased == customer2.items_purchased and customer1 < customer2 may look unusual.
If you use a linter, it may warn that the comparison result is unused.
But they are used!
Comparison operators are overloaded for Instance and InstanceProperty objects to return an Expression that specifies a condition for triggering the rule.
Like other Producer objects, expressions act as placeholders.
They aren’t Python Boolean values, so operators like and, or, and not aren’t supported.
See Filtering Objects by Property Value and A Note About Logical Operators for more details.
You can compute values on the graph, like the number of nodes and edges, using methods in the customer_graph.compute namespace:
## Get the number of nodes and edges in the graph.
with model.query() as select:
num_nodes = customer_graph.compute.num_nodes()
num_edges = customer_graph.compute.num_edges()
response = select(
alias(num_nodes, "nodes"),
alias(num_edges, "edges"),
)
response.results
# nodes edges
# 0 570340 18270309
Now that you have a graph, you can use a community detection algorithm, like the Louvain algorithm, to find segments of customers that are more connected to each other than to the rest of the graph.
The Louvain algorithm assigns an integer community ID to each node in the graph.
Customers with similar purchase behavior get assigned the same ID, and you can use these IDs to create a CustomerSegment type for each segment of customers:
## Define the CustomerSegment type.
CustomerSegment = model.Type("CustomerSegment")
# Use the Louvain algorithm to compute customer segments (communities).
with model.rule():
# Get an Instance that matches any Customer entity.
customer = Customer()
# Compute the customer's segment ID using the Louvain algorithm.
segment_id = customer_graph.compute.louvain(customer)
# Create a CustomerSegment entity for each segment ID.
segment = CustomerSegment.add(segment_id=segment_id)
# Set a multi-valued property on the CustomerSegment entity to customers in the segment.
segment.customers.add(customer)
# Set a single-valued property on Customer entities to their related CustomerSegment entity.
customer.set(segment=segment)
While you’re at it, define a rule that counts the number of customers in each segment and sets the size property on CustomerSegment entities:
## Set a size property on CustomerSegment entities that counts the number of
# customers in each segment.
with model.rule():
# Get an Instance that matches any CustomerSegment entity.
segment = CustomerSegment()
# Get an InstanceProperty that matches related Customer entities.
customer = segment.customers
# Count the number of customers in each segment.
segment_size = aggregates.count(customer, per=[segment])
# Set a single-valued size property on CustomerSegment entities to the segment size.
segment.set(size=segment_size)
Although you could have defined the size property in the same rule that computes the segments, it’s a good practice to break up your rules into smaller, more focused blocks.
Not only does this make your code easier to read and maintain, it also improves the performance of your queries.
To get a sense of how customers are distributed across segments, you can use pandas’ .describe() method to view summary statistics of the segment sizes:
## Get the ID and size of each segment.
with model.query() as select:
segment = CustomerSegment()
response = select(segment.segment_id, segment.size)
# View summary statistics for the size column in the results.
response.results["size"].describe()
# count 7769.000000
# mean 73.412280
# std 26.805404
# min 1.000000
# 25% 53.000000
# 50% 69.000000
# 75% 90.000000
# max 217.000000
# Name: size, dtype: float64
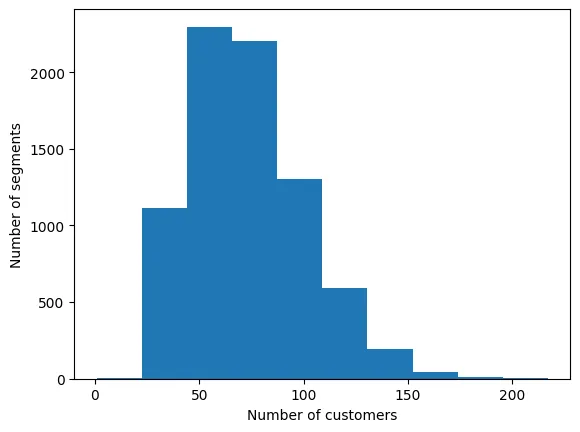
The Louvain algorithm identified 7,769 individual segments! The majority of the segments have between 50 and 100 customers. Let’s plot a histogram of the segment sizes to see the distribution of customers across segments:
## View a histogram of the number of customers in each segment.
response.results.plot(
kind="hist",
y="size",
ylabel="Number of segments",
xlabel="Number of customers",
legend=False,
)
Explore the Differences Between Customer Segments#
What makes each segment unique? There are many dimensions to explore, but let’s start by looking at the three most popular item categories in each segment.
To capture the concept of a “popular category”, let’s define a RankedSegmentCategory type that ranks the item categories by the percentage of customers in a segment that have purchased items from each category:
#RankedCategory = model.Type("RankedCategory")
with model.rule():
segment = CustomerSegment()
customer = segment.customers
item = customer.items_purchased
category = item.category
# Compute the category rank as the percentage of customers in the segment
# that have purchased any item in the category.
category_rank = aggregates.count(customer, per=[category, segment]) / segment.size
# Add a RankedCategory entity for each segment-category pair.
ranked_category = RankedCategory.add(segment=segment, category=category)
# Set the rank property on RankedCategory entities.
ranked_category.set(rank=category_rank)
# Connect segments to their ranked categories.
segment.ranked_categories.add(ranked_category)
Let’s query the model to see the top three item categories in the first five segments:
#with model.query() as select:
segment = CustomerSegment()
# Filter for segments with IDs between 1 and 5.
1 <= segment.segment_id <= 5
# Filter for the top 3 categories in each segment by rank.
category = segment.ranked_categories.category
rank = segment.ranked_categories.rank
aggregates.top(3, rank, category, per=[segment])
# Select the segment ID, category name, and rank.
response = select(segment.segment_id, category.name, rank)
response.results
# segment_id name rank
# 0 1 Children: infants 0.450820
# 1 1 Shoes: womens 0.680328
# 2 1 Sports: football 0.516393
# 3 2 Books: romance 0.479592
# 4 2 Jewelry: gold 0.551020
# 5 2 Music: country 0.836735
# 6 3 Children: school-uniforms 0.525424
# 7 3 Home: flatware 0.559322
# 8 3 Sports: football 0.830508
# 9 4 Books: entertainments 0.584615
# 10 4 Jewelry: womens watch 0.861538
# 11 4 Sports: football 0.615385
# 12 5 Children: infants 0.663158
# 13 5 Jewelry: estate 0.526316
# 14 5 Sports: athletic shoes 0.694737
This query gives you a sense of the different kinds of items that customers in each segment are interested in.
Further analyses can be done to explore the differences between segments in more detail.
For instance, the top category for segments 1 and 5 is Children: infants, but customers are likely purchasing different items within those categories.
To explore the connections between segments and their top categories, you can visualize segments and categories as a graph.
The following creates a new Graph object with CustomerSegment and RankedCategory nodes and edges between segments and their top five categories:
#segment_category_graph = graphs.Graph(model)
with model.rule():
customer = Customer()
segment = customer.segment
category = segment.ranked_categories.category
rank = segment.ranked_categories.rank
# Limit the graph to the top 15 largest segments.
aggregates.top(15, segment.size, segment)
# Limit the graph to the top 5 categories per segment by rank.
aggregates.top(5, rank, category, per=[segment])
# Add SegmentCategory nodes to the graph.
segment_category_graph.Node.add(
category,
label=category.name,
# Scale the node based on the average number of customers that have purchased
# items from the category per segment.
size=(aggregates.count(customer, per=[category]) / aggregates.count(segment, per=[category])),
label_size=30,
color="cyan",
shape="hexagon"
)
# Add RankedSegment nodes to the graph.
segment_category_graph.Node.add(
segment,
label=segment.segment_id,
# Scale the node based on the number of customers in the segment.
size=segment.size,
label_size=30,
color="magenta",
shape="circle"
)
# Add edges between segments and categories. The width (size) of the edge is
# based on the rank of the category in the segment.
segment_category_graph.Edge.add(segment, category, size=rank)
# Visualize the graph.
fig = segment_category_graph.visualize(
graph_height=800,
node_hover_neighborhood=True,
use_node_size_normalization=True,
node_size_normalization_min=30,
use_edge_size_normalization=True,
layout_algorithm="forceAtlas2Based",
)
# Display the visualization.
fig.display(inline=True)
Use your mouse to zoom in and out of the graph. You can click and drag nodes to reposition them, and open the menu on the right-hand-side of the figure to adjust visualization settings and export the graph as an image.
You may also export the visualization as a standalone HTML file so that it can be shared with others:
#fig.export_html("segment_category_graph.html")
Export Segment Data to Snowflake#
Now that you’ve identified segments of customers with similar purchase behavior, you can export the segment data to Snowflake where it can be incorporated into existing SQL workflows or used to generate reports.
First, query the model for the customer IDs and segment IDs of each customer.
Set the format="snowpark" parameter in the model.query() function to export the query results to a temporary Snowflake a table and return a Snowpark DataFrame object that references the table:
#with model.query(format="snowpark") as select:
customer = Customer()
segment = customer.segment
response = select(customer.customer_id, segment.segment_id)
# Display the results. Only the first 10 rows are shown.
response.results.show()
# --------------------------------
# |"CUSTOMER_ID" |"SEGMENT_ID" |
# --------------------------------
# |46724428 |1 |
# |61448936 |2 |
# |27837860 |3 |
# |35582320 |4 |
# |54875589 |5 |
# |31123522 |6 |
# |1142318 |7 |
# |35550549 |8 |
# |5771146 |9 |
# |48296113 |10 |
# --------------------------------
Refer to the Snowflake documentation for more information on working with Snowpark DataFrames.
Let’s merge the segment data with the SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.CUSTOMER table to get more information about the customers and save the results to a new table in the RAI_TUTORIAL.TPCDS schema:
## Get the model's Snowflake Session object.
session = model.resources.get_sf_session()
# Get the sample customer table.
customers = session.table("SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.CUSTOMER")
# Join the results with the customer table on the CUSTOMER_ID and C_CUSTOMER_SK columns.
customers_with_segments = (
response.results
.join(customers, response.results["CUSTOMER_ID"] == customers["C_CUSTOMER_SK"])
.select(customers["*"], response.results["SEGMENT_ID"])
)
# Save the results to a new table in the RAI_TUTORIAL.TPCDS schema.
(
customers_with_segments.write
.save_as_table("RAI_TUTORIAL.TPCDS.CUSTOMER", mode="overwrite")
)
You can now use the RAI_TUTORIAL.TPCDS.CUSTOMER table, which has a SEGMENT_ID column containing the segment IDs computed by the RAI model, to feed into your existing SQL workflows, generate reports, perform further analyses, or consume the data in an application.
Summary and Next Steps#
In this tutorial, you learned how to create a RAI model of retail business sales using a portion of the TPC-DS dataset available in Snowflake.
You saw how to:
- Define types from Snowflake tables.
- Define types without source tables.
- Enrich types with additional properties and relationships using rules.
- Build a graph and use a graph algorithm.
- Visualize parts of the model as a graph.
- Export model data to Snowflake.
In the next part, you’ll take the model you built in this tutorial and use it to build a Streamlit app.