What’s So Special About Graph Analytics?

I’m often asked, “What’s so special about graph analytics?” And my answers range from, “They allow us to look at the structure of our data instead of just the data points,” and “They uncover patterns and predictive information,” to the simple, “They infer meaning from connections,” or “They’re just plain magic.”
The last response is my favorite because it captures how many of us who think about networks end up feeling about graph analytics.
A few weeks ago I had the opportunity to share a few examples illustrating why graph analytics feel so magical and how they differ from typical analytics. I was invited to participate in the Distinguished Speakers Series hosted by G-Research (opens in a new tab) in London.
Watch my complete talk, Average is a Lie: Using Graph Analytics to Improve Predictions
Magical Discoveries
Part of what makes graphs feel like magic is how they reveal non-intuitive insights. I started my talk with some surprising research results about voting behavior.
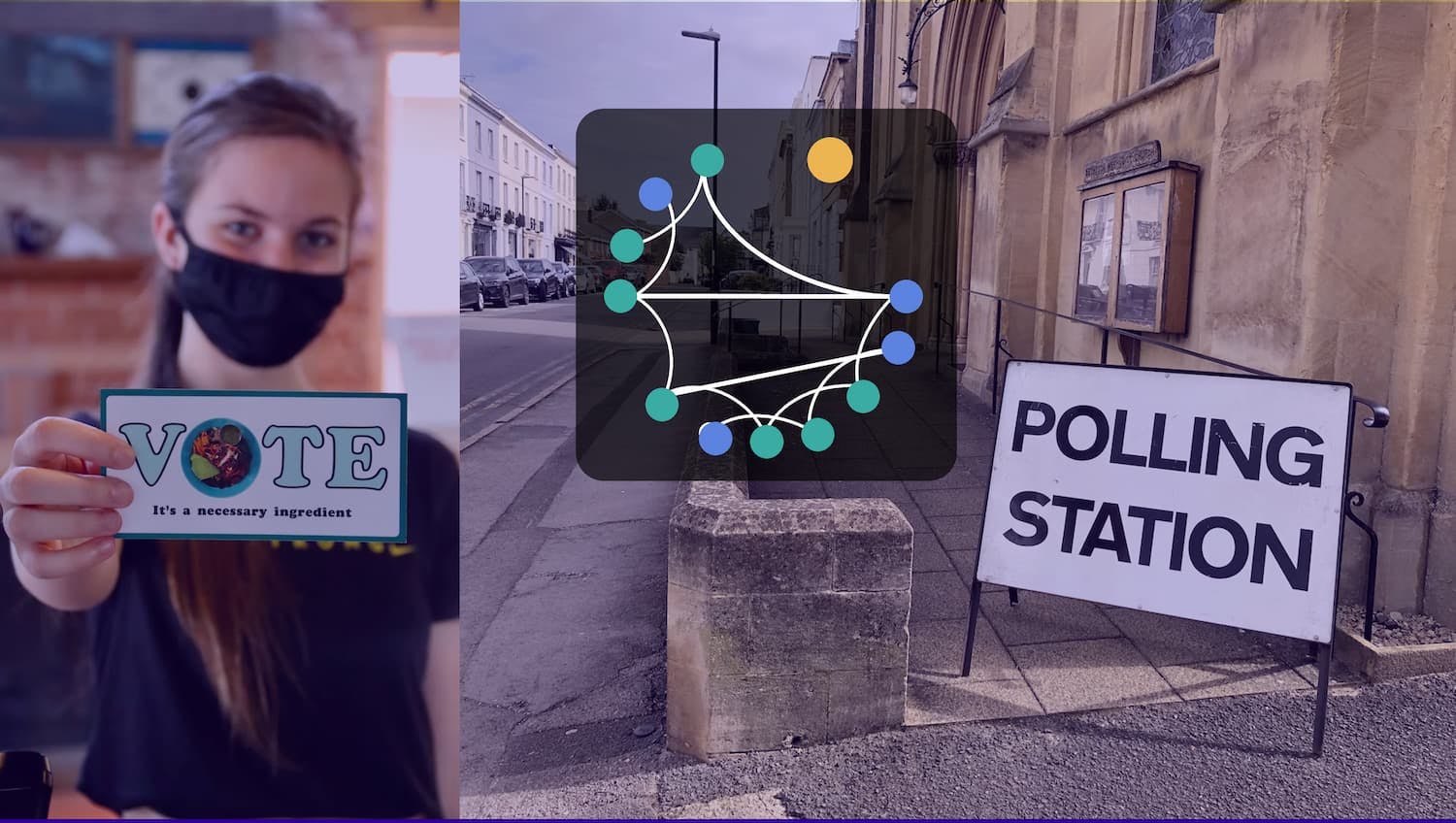
It turns out that predicting whether or not you are going to vote, based on data about you as an individual (things like your age, financial status, where you live) are actually not the most predictive elements. Research shows that your network of friends is more predictive of whether you would vote.
In other words, people we don’t even know directly are more telling about our own behavior.
Average is a Lie
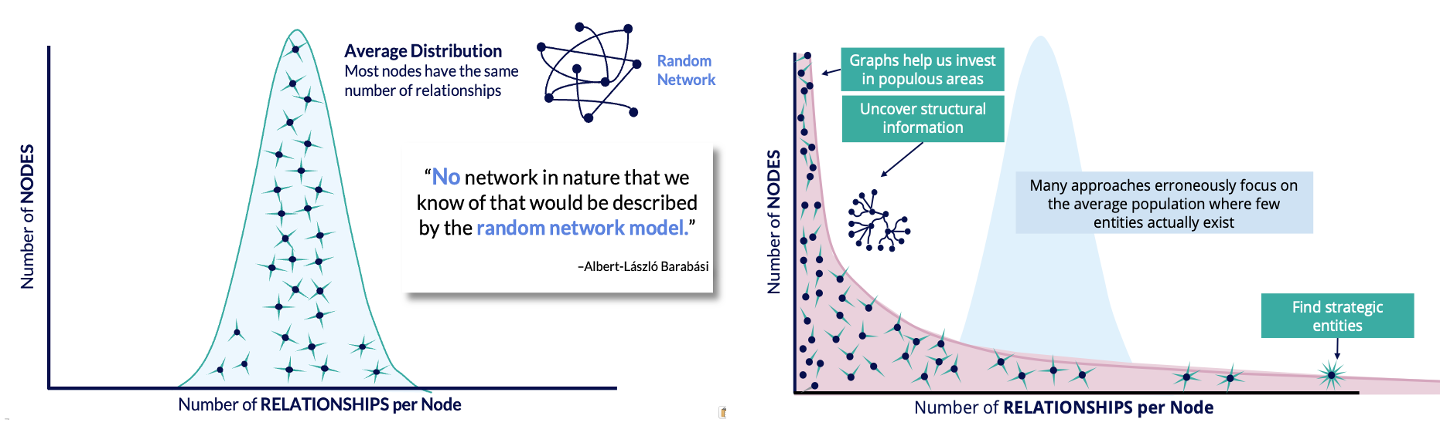
We then looked at how most people approach analyzing networks, which is to assume most things (people, websites, etc.) have an average number of connections with a classic Gaussian curve (opens in a new tab).
However graph analytics helps us “see” that most things have fewer connections, but some outsized entities have a lot of relationships. In this sense, average is just a concept that not only doesn’t represent any real-world systems, but can also lie to you, hiding important features of your data.
Graph Analytics See Shapes and Infer Meaning
Graph analytics help us make sense of our connected data by understanding the structure of our data. They help us see which patterns are important and which aren’t. They help us predict what’s coming next. And they help us find control points so that we can be prescriptive and enact change.
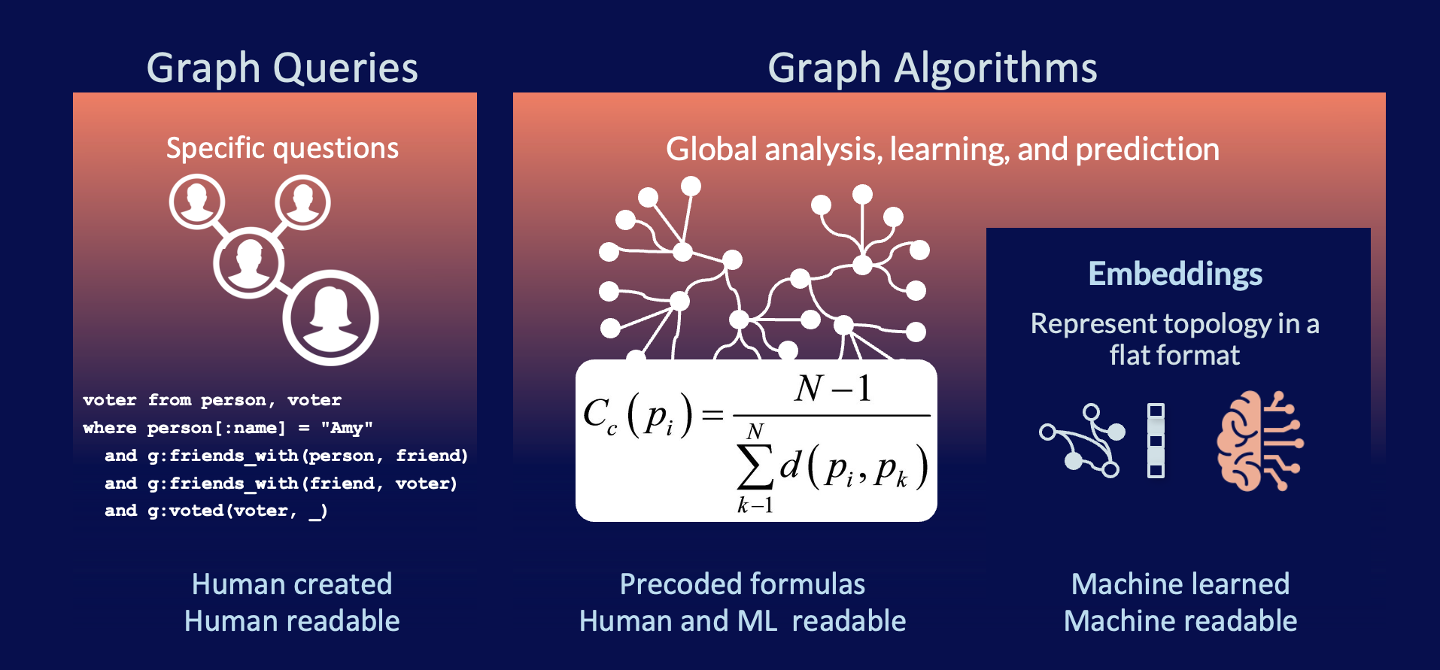
This means we can ask better questions of our data. We know what we’re looking for and we can ask very specific questions looking for real-time and local decisioning. Things like, how many of Amy’s friends’ friends voted? These are human-created questions that are human readable.
With graph algorithms we might also be looking for more global analysis, inferring meaning and learning as well as making predictions. Asking questions like, who is the most influential person in the network? Or, which access point can reach critical assets the fastest? These use preformatted formulas but the output is human readable: a score and group identification.
Graph Analytics Uses
We then turned to example uses of graph algorithms, from supply chain optimization and data lineage to analyzing financial contagion and security issues.
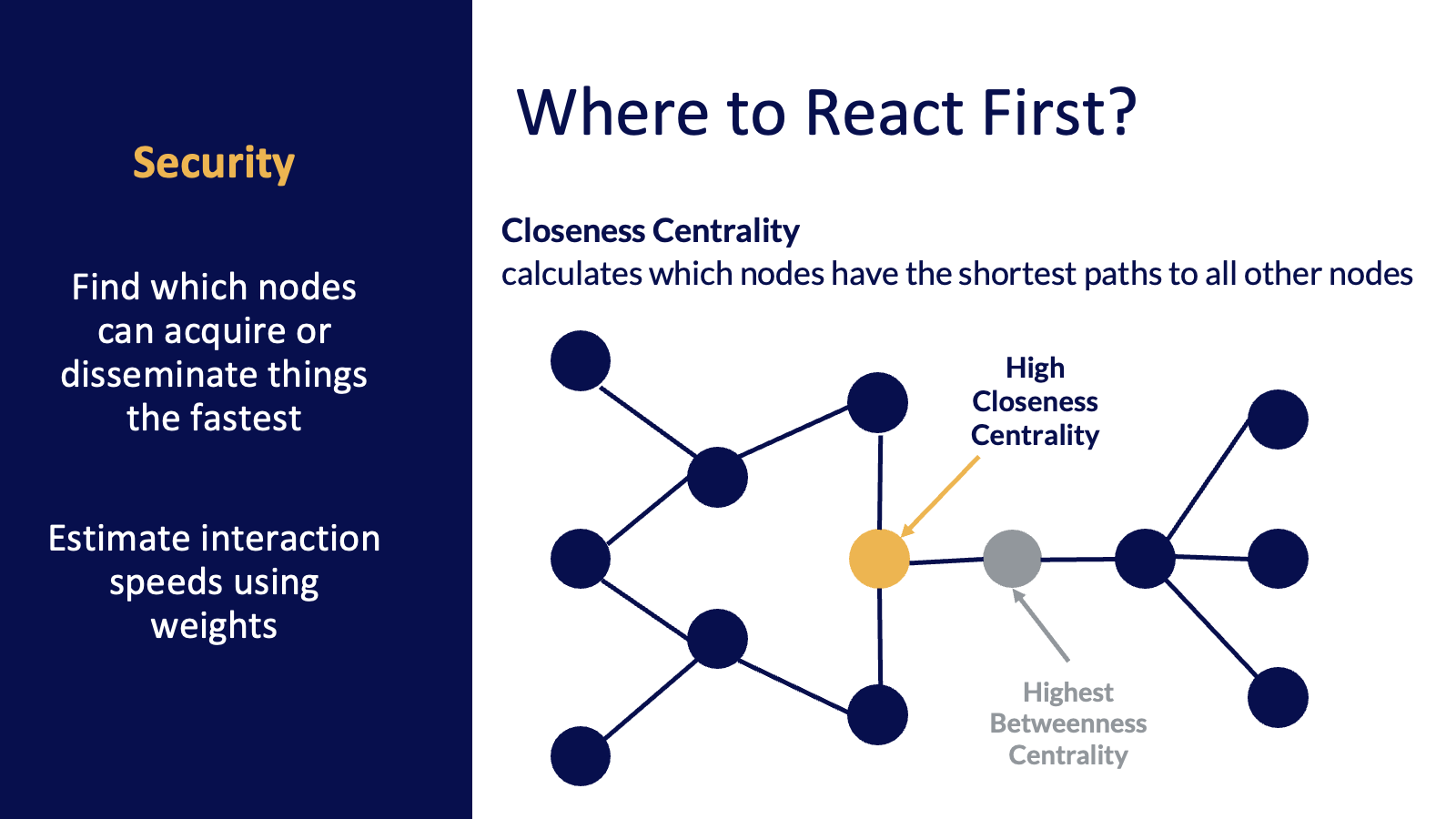
For example, if we have a security breach, where would we want to react first? At the point of entrance? Or maybe we need to protect the access point that has the most direct access to all other points.
The Closeness Centrality algorithm looks at the number of shortest paths to find which node can most quickly touch every other node. Weighing the relationships in Closeness Centrality has been used to estimate the speed of spread of information in both criminal and telecom networks.
Or maybe we are more interested in Betweenness Centrality, which finds choke points and bridges so we can break our network apart to protect a critical asset.

I ended the talk covering some practical tips about working with graphs but also some personal advice. Research has shown that people have higher pay and more promotions when they don’t follow the normal hierarchical ladder — but instead move between organizations and have career shifts.
So as I always do, I encouraged the audience to meet someone new and follow up at least once. I had some very interesting conversations that night and made some fantastic connections.
Related Posts

Parsing the Crowded World of Data Analytics: Highlights
Our board member Bob Muglia recently met with Sanjeev Mohan in an interview for the It Depends podcast. Bob and Sanjeev discussed the challenges, trends, technologies and the general pulse of the ever-changing data analytics market. Here are some highlights from their discussion!

RelationalAI CLI and Public GitHub Repo
We are excited to announce the RelationalAI Command-Line Interface, which is used to interact with the Relational Knowledge Graph Management System (RKGMS).