
Metadata Management Series: Weaving Asserted and Discovered Metadata into Your Data Fabric
This series of articles will show how knowledge graphs support the construction of scalable models that mix discoverable with explicitly asserted metadata to afford reasoning and policy enforcement. In this first article, we show how explicitly asserted metadata in a knowledge graph enables automated reasoning.
What is Metadata Management?
Data architects create models of their data assets for various purposes, including documentation, optimization, search, classification, and policy enforcement. These models contain “information about data” or metadata. Metadata such as the names and types of tables and columns can be discovered and maintained automatically. And some of these metadata can be automatically linked to one another to represent important relationships like the containment of a column in a table or the lineage of data among assets, such as when a table is constructed using an ETL script.
Unfortunately, some important metadata and some links that connect metadata cannot be discovered automatically. While this is not a new problem, we are seeing it increase as organizations migrate to the Cloud and begin to adopt architectural practices that separate and encapsulate data assets. Data architects compensate by building up a store of asserted knowledge – statements of fact about the semantics of data assets and of connections between them.
Asserted knowledge is another kind of metadata – one that references and depends on the discovered metadata that is automatically discoverable and maintainable using tools. Asserted knowledge is typically informal, and if it is recorded at all, it is in the form of code comments, documents, or spreadsheets. Despite its informality, architects rely on asserted metadata to reason or enforce policy to the point that business outcomes depend on its veracity.
We believe that to properly manage and enforce policy over data assets at scale, asserted metadata should be woven with discovered metadata into a knowledge graph that affords powerful reasoning.
The Need for Asserted Metadata
Consider a hypothetical enterprise with two micro services:
FundManager, which owns the XYZ_Txns table among others, and SecurityManager, which manages a system-of-record database of securities.
Suppose FundManager uses a lookup service provided by SecurityManager to look up securities based on some request parameters as depicted here:
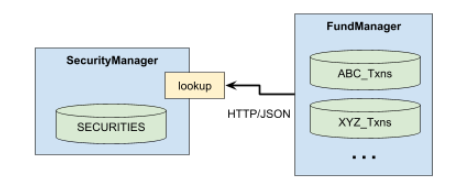
Now imagine, that SECURITIES was created as follows:
CREATE TABLE SECURITIES(
ID uniqueidentifier PRIMARY KEY,
Ticker varchar(8)
CUSPID varchar(16)
...
)Suppose FundManager calls lookup to retrieve an authoritative ID to use as the value for a column named SecId when it creates new rows in the XYZ_Txns table. When the architect learns this fact, she realizes that if the tables were in the same database, she could relate SecId and ID by a FOREIGN KEY constraint, but because they live in different micro services, it is not possible to declare and enforce such a constraint.
That information was likely not discoverable automatically. Maybe SECURITIES once lived in FundManager where a FOREIGN KEY constraint enforced the connection between ID and SecId, but when a decision was made to split FundManager into two microservices, this information and the guarantee of data integrity were lost.
In any case, this semantic connection is significant and could be used to reason about compliance with certain governance policies. For instance, consider the requirement that the security attributes of every transaction in FundManager are auditable. Those attributes are not part of the XYZ_Txns table, but they are part of SECURITIES. If each attribute is declared NOT NULL in SECURITIES, if SecId is declared NOT NULL in XYZ_Txns (as it is), and if this asserted link from ID to SecId is akin to a FOREIGN KEY constraint, then the data architect should feel confident that the attributes are guaranteed to exist for each SecId and so the requirement is satisfied.
Reasoning over Metadata
This example provides just one illustration of the kind of reasoning a data architect must do over the metadata she manages. Notice that a key step in this reasoning uses asserted knowledge that refers to metadata (the columns ID and SecId) that are discovered automatically. Without that step, the chain of reasoning breaks, which leaves her potentially in violation of this particular requirement. It is therefore critical that she records this assertion so that this reasoning can be automated. It is also important to protect this assertion from drifting with respect to the discovered metadata (columns ID and SecId) that it references.
The next articles in this series will discuss how to weave this kind of asserted metadata into our model and how to prevent drift. We will examine how the facilities of knowledge graph management systems help with practical issues that arise when managing models containing both types of metadata.