
Machine Learning in Consumer Credit: A Knowledge-Driven Approach to Mitigating Bias
The financial services sector was one of the first industries to widely adopt predictive modeling, starting with Bayesian statistics in the 1960s and evolving after the advent of neural networks to deep learning and beyond. Machine learning applications in this industry are endless, whether in auditing, fraud detection, credit scoring, or others. These use cases have only increased as technology has improved and become more commercialized.
However, regulatory guidelines are still evolving as technology and applications rapidly change. Despite the widespread deployment of predictive and machine learning models, much of the research and frameworks around explainability and transparency in consumer credit lagged in adoption and the ability to be implemented at the same scale to ensure inclusive economic growth. As a result, modern models are often based on historically biased data and therefore impact individual lives.
In the United States, over 40 million people have no credit score, and more are classified as having bad credit. These two groups are often treated the same and denied financial support --- decisions now usually made in tandem with data or machine learning models --- and little recourse is provided as to why this decision was made or what they can do about it. Unfortunately, Black Americans are disproportionately impacted and comprise a large percentage of this group.
As we think about creating rights-preserving technology that is financially inclusive of diverse groups, we must ask ourselves:
What do we mean by fairness, transparency, and explainability? How do we proactively mitigate bias in data and machine learning models? How do we help people drive a different outcome?

Consumer credit panel discussion from the Stanford HAI event. Image from this video source.
These are the topics many of us across the private and public sectors wanted to explore and offer innovative research on, and why we collaborated with FinRegLab in what ultimately culminated in a white paper and symposium hosted by the U.S. Department of Commerce and National Institute of Standards and Technology, Stanford Institute for Human-Centered Artificial Intelligence (HAI), and the FinRegLab.
At RelationalAI, we focused on applying domain knowledge, or semantics, to counterfactual explanations to generate actionable and computationally efficient explanations. Before we get into this, let’s take a step back and look at the landscape of explainability in machine learning.
Explainability in Machine Learning

The panel focused on explainability and fairness in machine learning. Image from this video source.
Research in this space has been going on since the early to mid-2000s, with early explanation techniques focused on feature attribution scores coming out around 2016. This includes well-known techniques like LIME and SHAP. These techniques, released more broadly in 2016 and 2017, are still being improved today and focus on answering the question of which feature played the most significant role in influencing a prediction. Other explanation techniques include rules-based explanations, explanations for deep nets, etc.
While the state-of-the-art in explanations is constantly evolving as machine learning as a field continues to grow, what we at RelationalAI attempted to address in this research collaboration is the gap in ensuring consistent, actionable explanations that are also computationally efficient to produce. This is an important aspect to manage, especially in the context of adverse action, since any consumer-facing prediction (especially if declined) should be accompanied by a method of recourse that a customer could act on.
To do this, we incorporated the following research, GeCo, into the collaboration.
Using Knowledge to Create Actionable Explanations
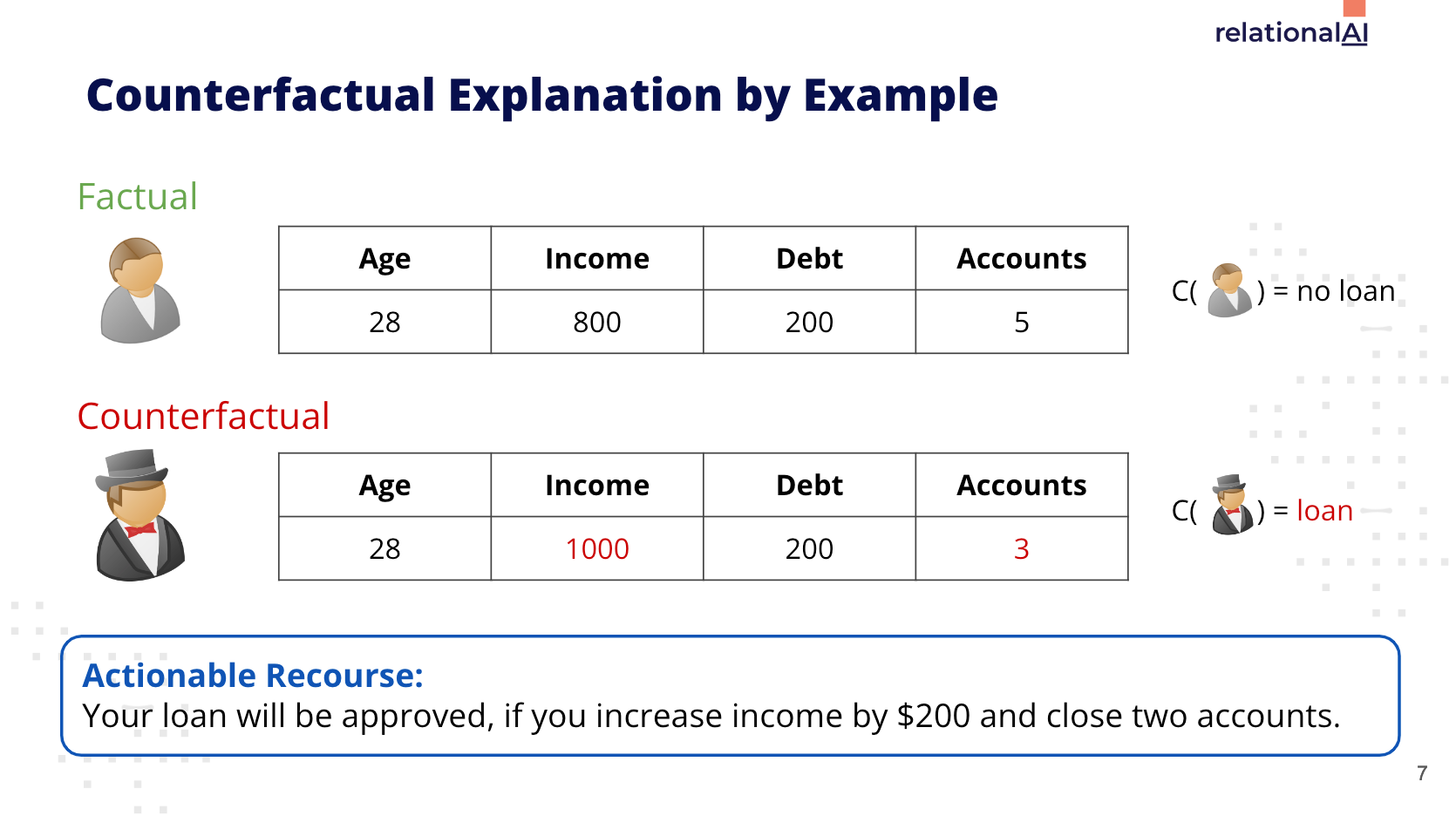
Illustration of a counterfactual explanation. Image from Max Schleich’s GeCo presentation.
At a high level, the way counterfactual explanations can be leveraged in the real world is that if a loan applicant submits their information and receives a denial as an output of a machine learning model, a counterfactual explanation is provided alongside that prediction that explicitly calls out what it would take to be approved.
In the simple example scenario above, increasing the submitted income by $200 and closing two accounts would be a form of actionable recourse by the applicant.

Description of how counterfactual explanations work. Image from Max Schleich’s GeCo presentation.
A common challenge with explanations, in general, is that many are not computationally efficient to produce. The realm of possibilities as to which variables can be toggled or adjusted to generate explanations is a massive search space. On top of that, many of the explanations generated are not even actionable by a consumer, resulting in significant amounts of wasted computation, money, and time.
For instance, we would not want to include any results that require a decrease in age, or starting and securing a Ph.D. in one year.

Example of how domain knowledge, or constraints, can be implemented to generate actionable recourse. Image from Max Schleich’s GeCo presentation.
The critical differentiator to our approach to counterfactual explanations is the incorporation of knowledge through constraints expressed via declarative programming.
This effectively does two things:
Reduces the search space, saving time and money (also making it easier to operationalize counterfactuals as part of a production process) Produces actionable recourse, mitigating adverse impacts to the customer
This is just one area where we see the opportunity to combine knowledge with data to unlock new capabilities in financial services, especially in the explanations space.
An Opportunity to do More
Like other areas of machine learning and AI, the field of explainable AI or responsible AI is constantly evolving. We also wanted to explore many different areas, but we have slated these for future research.
Other active research we would like to explore includes:
Building counterfactually fair models up-front with causal models. This would address issues where bias can manifest in the data despite taking out certain variables for regulatory purposes due to causal relationships in the data. Exploring the latest developments from Hema Lakkaraju and some of the OpenXAI research around effective benchmarking for explainability techniques. Since so many different explanation techniques are emerging, there is a challenge in standardizing and measuring their efficacy.
Given the complexity of bias in machine learning and AI, specifically bias in models used for consumer credit, it seems likely additional research and an ensemble of techniques are required to address different parts of the deployment process. There is not yet one model to rule them all.
Additional References
White paper from FinRegLab Accelerating AI Adoption with Explainability in SaMD GeCo: Quality Counterfactual Explanations in Real Time A Language for Counterfactual Generative Models Explaining Explanations: An Overview of Interpretability of Machine Learning FinRegLab Podcast: We discuss causal inference in machine learning with Molham Aref, CEO of RelationalAI