Hybrid and Content-based Recommender Systems in Rel - Part 3

In our two previous posts, we looked at graph-based and neighborhood-based recommender systems. We focused on generating recommendations using only user-item interactions, an approach known as collaborative filtering.
However, more information is usually available, which can drive a content-based approach. For example, a movie recommendation is usually based on information about the movie itself, such as the genre and actors.
The content-based approach can be combined with the collaborative filtering approach to create what is known as a hybrid recommender system. The most popular example of a hybrid recommender system is Netflix.
To recommend movies to users, Netflix uses both the watching habits of similar users (collaborative filtering), as well as movie characteristics, such as genres the user previously showed interest in (content-based filtering) to make recommendations.
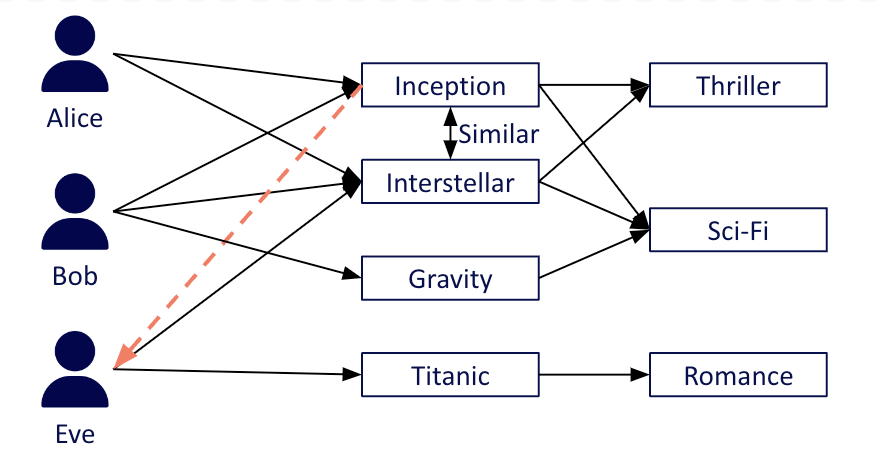
Example of the hybrid approach
The Content-based Approach
Previously, we modeled the user-item interactions as a bipartite graph consisting of two node types: User and Movie. In this example, we are using the content-based approach, where the graph is augmented by a new node type: Genre.
In other words, we now deal with a tripartite graph, shown in the figure below. Note that the tripartite graph model can easily be extended into richer graphs by adding more node types, for example, actor, director, and so on.
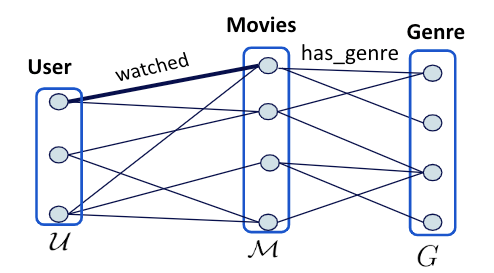
The tripartite graph representation of the MovieLens dataset.
This additional node type is modeled in Rel as a value type as follows:
entity type Movie = Int
entity type User = Int
value type Id = Int
value type Name = String
// add genre value type definition (a genre is identified by its id)
value type Genre = IntAfter defining our additional node type, we need to modify the Movie entity by adding the edge has_genre that connects a Movie to its genres.
The has_genre relation assumes there is another relation movie_info(movie, movie_name, genre_id) that contains movie names and genres (a movie can be assigned multiple genres). The data in the movie_info relation is provided by MovieLens (opens in a new tab).
// write query
module movie_info
// entity node: Movie
def Movie =
^Movie[m : watched_train(_, m)]
// edge: has_id
def has_id(movie, id) =
movie = ^Movie[m] and
id = ^Id[m] and
watched_train(_, m)
from m
// edge: has_name
def has_name(movie, name) =
movie = ^Movie[m] and
name = ^Name[n] and
watched_train(_, m) and
movie_info(m, n)
from m,n
// edge: has_genre
def has_genre(movie, genre) =
movie = ^Movie[movie_id] and
genre = ^Genre[genre_id] and
movie_info[movie_id, _, genre_id]
from movie_id, genre_id
end
// store the data in the `MovieGraph` base relation
def insert:MovieGraph = movie_infoWe can now use the relation has_genre to compute similarities using similarity metrics such as cosine, jaccard, and dice.
There is one core difference between the item- and user-based approaches and the content-based approach. In the content-based approach, we calculate similarities using the relation has_genre which contains (movie, genre) pairs, instead of the relation rated_t which contains (movie, user) interaction pairs.
For the rest of this implementation, we follow the same pipeline as in our neighborhood-based approach. Below is a sample run that generates recommendations and evaluates them using the content-based method:
with MovieGraph use has_genre, rated_t, Movie
with MovieGraph_test use evaluation_sample, User
def k_neighbors = 20
def rating_type = :binary
def k_recommendations = 10
// (movie, user)
def ratings = rated_t
// (movie, genre)
def content_information = has_genre]
def approach = :item_based
// define the (movie, genre) undirected graph
def G = undirected_graph[content_information]
with rel:graphlib[G] use jaccard_similarity
def sim[m1, score, m2] =
score = -jaccard_similarity[m1, m2] and
Movie[m1] and Movie[m2] and
m1 != m2 and
abs[score] != 0
def get_item_scores = pred[approach, rating_type, k_neighbors, rated_t, sim, top_k]
def top_k_recommendations(user, rank, movie) =
top[k_recommendations, get_item_scores[user]](rank, score, movie)
from score,pos
def predicted_ranking = top_k_recommendations
def target_ranking = MovieGraph_test:rated
def output = average[precision_at_k[k_recommendations, predicted_ranking[u], target_ranking[u]] <++ 0.0 for u where User[u]]The Hybrid Approach
The Netflix model uses a hybrid approach, which computes the similarity between distinct items by combining user- and item-based approaches and content-based filtering.
This idea is materialized in Rel by defining a module named hybrid_feature. This module takes the following parameters as input:
- M: The relation containing (movie, user) pairs.
- C: The relation containing (movie, genre) pairs.
- W: The parameter that controls the relative importance of the content features. When w is 0, this is equivalent to the user- and item-based approach, i.e., only having (movie,user) pairs. As w increases, so does the importance of the content features. A w value of 1 implies that user/item-based and content-based features have the same weight.
@outline
module hybrid_feature[M, C, W]
def rated_value_binary(movie, user, 1.0)=
M(movie, user)
def weighted_content_value(movie, genre, content_value) =
C(movie, genre) and
content_value = W
// movie, user, 1 OR
// movie, genre, content_weight
def hybrid_feature_value =
rated_value_binary ;
weighted_content_value
def hybrid_feature_value_t(feature, movie, v) =
hybrid_feature_value(movie, feature, v)
endThis hybrid feature is then used to calculate item-item similarities. Below is a sample run that generates recommendations and evaluates them using the hybrid method.
with MovieGraph use has_genre, rated_t, Movie
with MovieGraph_test use evaluation_sample, User
def shrink = 0
def k_neighbors = 20
def rating_type = :binary
def k_recommendations = 10
def ratings = rated_t
def approach = :item_based
def cw = 0.2
with hybrid_feature(rated_t, has_genre, cw) use hybrid_feature_value
def hybrid_information(movie, feature) = hybrid_feature_value(movie, feature,_)
// define the (movie, feature) undirected graph where the feature could be a user or a genre
def G = undirected_graph[hybrid_information]
with rel:graphlib[G] use jaccard_similarity
def sim[m1, score, m2] =
score = -jaccard_similarity[m1, m2] and
Movie[m1] and Movie[m2] and
m1 != m2 and
abs[score] != 0
def get_item_scores =
pred[approach, rating_type, k_neighbors, ratings, sim, top_k]
def test_items_scores[user, score, movie] =
get_item_scores[user, score, movie] and evaluation_sample(user, movie)
def top_k_recommendations[user, rank, movie] =
top[k_recommendations, test_items_scores[user]](rank, score, movie)
from score
def predicted_ranking = top_k_recommendations
def target_ranking = MovieGraph_test:rated
def output = average[precision_at_k[k_recommendations, predicted_ranking[u], target_ranking[u]] <++ 0.0 for u where User[u]]Results and Next Steps
In our experiments on the MovieLens100K dataset, the content-based and hybrid approaches achieve precision of 7.4% and 33.2% for k = 10 respectively. The results are in accordance with the literature for the content-based and hybrid classes of algorithms.
The evaluation scores show that the collaborative filtering approach (which has a maximum precision of 33.6% for k = 10) outperforms both the content-based and hybrid approaches. This can be attributed to the high density of the user-movie interactions, as the MovieLens100K dataset provides a minimum of 20 ratings for each user. Real-world datasets are significantly sparser, and thus are expected to significantly benefit from the hybrid approach.
We focused on a baseline content-based approach using only the genre information provided by the MovieLens dataset. However, the problem scope can easily be extended in Rel by providing additional content information (director, actor, and so on) from existing knowledge bases such as IMDB and DBPedia.
In this series of blog posts, we have shown how to implement neighborhood-based, graph-based, content-based, and hybrid recommender systems using RelationalAI’s declarative modeling language, Rel (opens in a new tab).
The implementations of these algorithms demonstrate the efficiency of our Relational Knowledge Graph System (RKGS) (opens in a new tab) for aggregating over paths on large and sparse graphs, computing similarities using our graph analytics library, and building compact, easy to read models, without needing to transfer data outside of our system.
Read the entire blog series on Recommender Systems in Rel:
- Neighborhood-based Recommender Systems in Rel - Part 1
- Graph-based Recommender Systems in Rel - Part 2
- Hybrid and Content-based Recommender Systems in Rel - Part 3
Related Posts

Graph-based Recommender Systems in Rel - Part 2
In our previous blog post, we explained how to model traditional neighborhood-based recommender systems in Rel. In what follows, we focus on modeling graph-based recommender systems.

Worksheets in the RAI Console
We are excited to announce worksheets, a new interface for submitting Rel queries. Worksheets allow you to develop blocks of Rel code and run them against a database. They can be shared with other users using their URLs.