Trends and Progress in Artificial Intelligence from ICLR 2021: Language Models & Data Programming
Introduction
Language models have become prevalent in almost every way we interact with technology today. Any time an ask is made of Siri, Alexa, Google Assistant, search engines, or other methods using language, language models are invoked to help us do everything from answer questions to translate bodies of text.
Because of the astounding success of technologies such as GPT-3 (opens in a new tab), language models are dominating not only our daily interactions with technology via over 300+ known apps today, but the academic field as well: almost any major publication you can think of has run something on them.
Despite all this popularity, we actually don’t know why language models are so effective. Recent scholarship (opens in a new tab) has offered mathematical explanations for the effectiveness of language models. But in a more intuitive sense, language models store knowledge inside a network that can do efficient inference. With very few labels, a program can create an application. This is also referred to as few shot learning, or learning from only a handful of examples—humans are good at this.
In this series, we are going to talk about these trends and more in artificial intelligence spotlighted at ICLR 2021 (opens in a new tab), with a specific focus on massive language models and related areas. Language models and data programming are the two crucial concepts we’re discussing here; language models are manifested through two main technologies called transformers and self-supervision. Transformers are an architecture for converting (transforming) one sequence of text into another using two parts, an encoder and decoder. These concepts will be the basis for everything we cover.
At RelationalAI, we are particularly interested in how we can augment these foundational concepts and make them both more powerful and more accessible, as language models can be expensive and limiting in who can leverage or develop them.
Key areas we can complement language models include:
-
Question answering
-
What: Being able to answer questions in human natural language
-
Complement: Enhance information retrieval and knowledge management
-
Reasoning
-
What: In a chess game, being able to predict if the next position is checkmate
-
Complement: Natively handle reasoning and complex rules within a system
-
Relation extraction
-
What: Extracting the relationship between concepts and terms
-
Complement: Construction of a knowledge graph or knowledge base
To this end, we will focus the first part of this series on the intersection of language models and increasing their accessibility without relying on massive amounts of data and through new methods of computation. Recent advances in this area, in addition to the use of transformers and self-supervision mentioned previously, make us challenge the use of compute versus memory, GPUs as a standard for deep learning, and even the way we think about the sparse nature of updates in large networks.
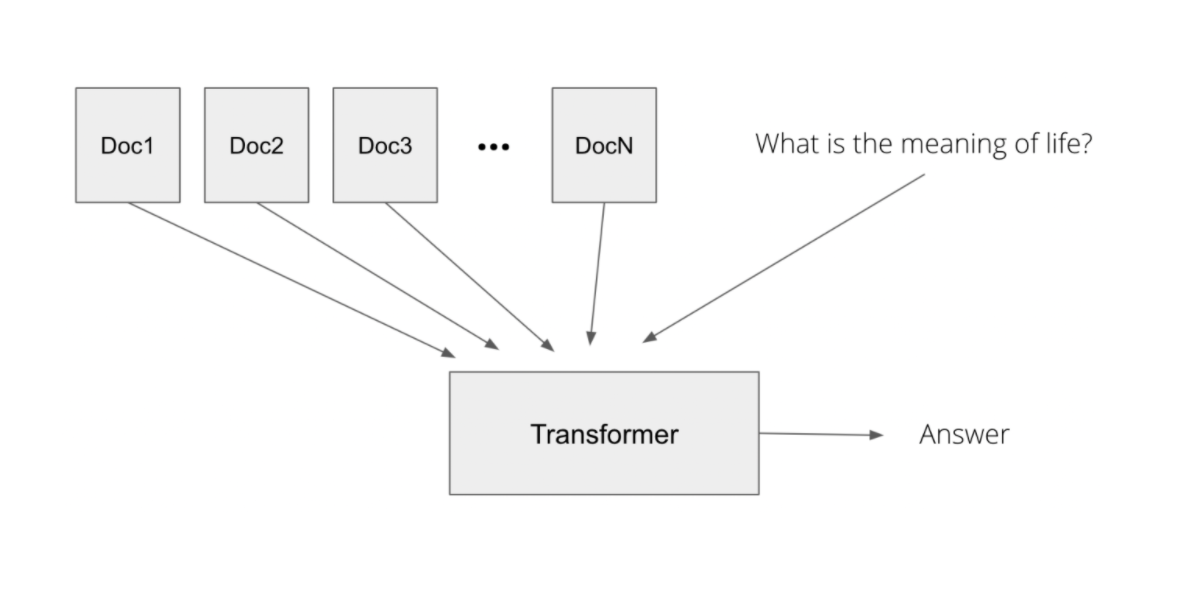
We will close Part I with an information retrieval example that puts several of these concepts together.
The second half of this series will cover “Questioning the state of the art (SOTA)”, where we will examine and challenge the latest architectures and techniques used in language models today. Here, we explore everything from pruning neural networks to the distillation of models and even adding logic to enhance the text generation of transformers.
At RelationalAI, we believe that transformers should live in-database. Part II will conclude with an example that is the culmination of multiple concepts covered and shows why we believe transformers-in-database can both reduce the resources needed and supercharge models for all to use (opens in a new tab).