The False Dichotomy of ‘Graph vs. Relational’

Modern Workloads, Changing Solutions
Over 40 years after their first appearance, relational databases powered by SQL have become ubiquitous — they’re the market leader in sector after sector, and they power much of the world’s most important infrastructure. For most workloads, for most people, a relational database with SQL as the query language is the safe, fast, efficient, and economical choice.
As the volume and connectedness of our data has grown, however, we have seen that there are limits to the implementations and optimizations that form the basis for modern relational SQL products. Specifically, these implementations face performance and resource issues that have caused some enterprises to augment their traditional data stores with other solutions when they need to execute what are commonly known as ‘hybrid’ or graph workloads. What causes these limitations? Primarily, traditional SQL databases implement n-way joins as a sequence of pair-wise joins. As a result, it is a well-known issue that performance decreases for these SQL engines as the number of required joins, n, increases.
Most database and data warehouse applications attempt to mitigate these effects by storing the data in a partially normalized — or even denormalized — form. The issue here is that the user is not left with the modeling flexibility required for graph relationships. Going fully in the other direction, using fully normalized data, exacerbates the n-way join performance issue. You can see why the popular “graph vs. relational” narrative, which typically depicts these problem areas as fully distinct, breaks apart here: real world problems combine both.
Another major attempt to solve these issues comes in the form of navigational graph databases. People navigate and reason through life with relationships, so navigational graphs feel natural. Many enterprises have adopted graph databases that physically store their data in the same way users visualize their graph: as nodes and pointers (edges). This tends to match users’ instinctive way to think about the graph, but the navigational approach is less effective and less scalable at the query engine level. Navigational queries must be modified if the graph shape is modified. Whole-graph queries are typically implemented as a node-by-node iteration of single-source queries. And semantic optimization is not possible with navigational queries.
So how do we proceed? We believe that modern workloads benefit from a platform that manages graph data structures on fully normalized relational data, with a query language that supports relational expressions and graph algorithms with equal ease. Taking inspiration from relational SQL databases, graph database research has achieved breakthroughs in algorithms and storage technology that have allowed for what used to be a holy grail: the storage of completely normalized data with a query engine that doesn’t generate the volume of intermediate data that traditional systems do.
A Recent Real-World Case Study
While we’re building out a cloud-native KGMS platform based on these principles of fully normalized data storage, we’re also developing solutions inside enterprises using our latest techniques. Graph-based problems are everywhere within companies that have lots of data and lots of application needs.
Recently, a major telephone company needed help with a massive influx of fraud data that traditional algorithmic techniques were struggling to handle. We developed new fraud detection algorithms by first taking a step back and modeling the data as a knowledge graph.
We started with a graph of callers and callees and found that trusted relationships are based on reciprocal calling behavior. For example, my Mom and I call each other frequently. This is a purely relational concept, and counting the degree of reciprocity for each edge in the graph is easier to do with a relational expression than a navigational one. Other examples included:
- Collections of callers that call amongst themselves represent a trusted community of callers.
- Legitimate sales campaigns involve a salesperson calling into a community (or affinity group) of people who have internal connections, for example, selling payroll software to HR professionals.
In general, community detection is best done with graph algorithms like weakly-connected-components. The knowledge graph and relational interface allowed us to naturally express the domain’s conceptual model and business rules distinguishing fraudulent robocalling from legitimate business activity.
RAI Puts It All Together
More and more companies are looking for solutions to their connected-data problems. RelationalAI’s platform was designed from the ground up to handle the types of hybrid workloads that typify this kind of modern data. Rather than trying to build a graph product on top of a SQL database, RAI has built a graph management system on a fully normalized relational data architecture. This approach to data storage architecture uses Graph Normal Form (GNF) because it is more flexible in allowing multiple models to be developed against the same physical data, and scalable up to trillions of rows (nodes and edges). To avoid pair-wise n-way joins, our platform relies on our dovetail join implementation of the worst-case optimal join algorithm, which makes fully normalized relational storage practical.
The diagram below gives an example of how the nodes, edges, and node- and edge-attributes of a simple labeled property graph are mapped to the fully-normalized GNF relations.
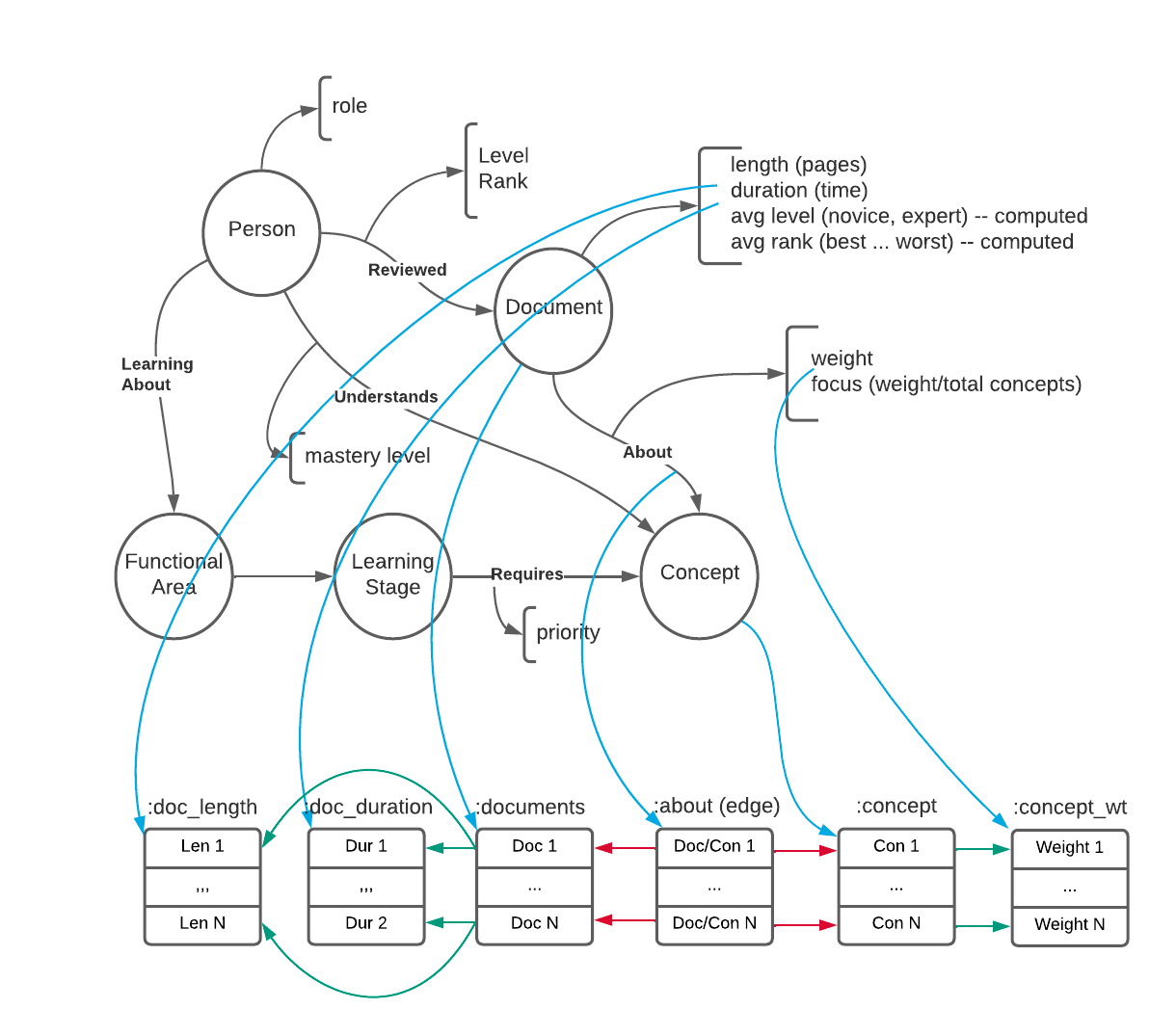
We have also developed Rel, our relational language which is concise, expressive, and explainable. We think of it as a power tool for developers, or executable specifications for business stakeholders — it’s designed to be clear and human-readable. The RAI platform also implements semantic optimization that exploits a graph’s schema, knowledge, and ontology to rewrite user queries into mathematically provably equivalent queries that are more performant. This cannot be done with navigational graph databases.
Rel serves as a solid foundation for other query languages. We intend to support SQL and other languages on top of Rel.
By combining the architectural benefits of relational with the conceptual intuitiveness of graph, we enable users to build abstract, high-level models and data apps on connected data sets. Contrary to the false dichotomy of graph vs. relational, RAI shows that relational is actually the best foundation for graph.
