Losing the Middle Tier

Unifying logic and data with RAI’s RKGS
The Northwind Traders database and schema, originally created by Microsoft, is a classic example of a typical small business database for tracking sales data. It includes tables containing business data such as products, orders, customers, and employees.
What’s great about this schema is that it has nothing to do with what most people intuitively think of as graph problems. It’s as mainstream as it gets.
We’re going to focus on a subset of the schema, the relationship between orders and order details, as an example of what it looks like to build applications with RAI’s Relational Knowledge Graph System (RKGS).
This subset of the data shows the relationship as you might query it from SQL, in a denormalized form. It includes such data as order id, unit price, quantity, discount, shipped date, etc.

Using this schema and data, we’ll demonstrate a simple business application scenario that reveals a complication in application design when using a traditional three-tier SQL-based architecture.
The Traditional Way
Let’s say we want to create a report that shows every order and the total price of the order. By looking at the schema and the example data, we determine that we need to calculate the total price value.
By looking at the schema and data above, it’s not completely clear how to calculate the total price per order. Most likely it is the sum of (quantity * unit_price * (1 - discount)) for all products in a given order. However, we can’t be 100% sure since the database model doesn’t guide us with a specific column or definition. Maybe the total price is actually just the sum of (quantity * unit_price) and the discount is just a historical record of the discount given by the sales person. Let’s just assume the formula requires us to calculate the discounted price and move on.
Since we’re writing a modern service-based application, we’re going to have an /orders service endpoint for querying order data. We imagine that computing the total price of an order will be a common occurrence, so we want to add this computed value to the /orders service. Now the question is, how do we get the value? One option would be to write a SQL query that does the computation when you query for it:

We need to know to issue this query any time we want the order’s total value. We could just query for the orders and all their order details and compute the value in Java or C# or whatever our middle tier is written in. We could also do some Object Relational Mapping (ORM) gymnastics to try to make our ORM generate the proper queries, but in general, adding nested relationships to an ORM is just asking for performance problems. Let’s stick with the SQL-only route for now, as we’ve written it.
Now that we have the total order value returned by the /orders service, let’s use the same logic to calculate the customer’s total lifetime value by summing up all the orders by customer, which we’ll make available through a /customers service call.
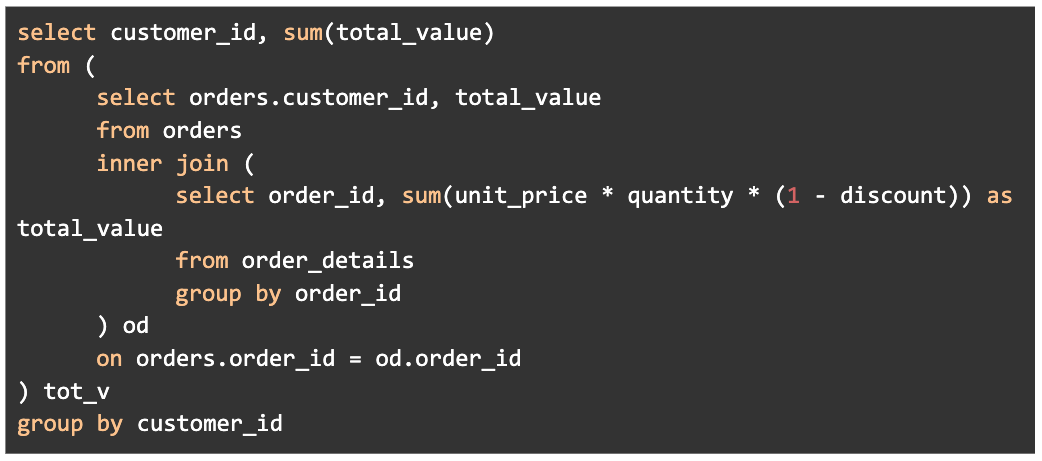
Uh-oh, that looks really familiar. What we’ve done here is nest the previous query inside this one. Not only does this make our query more difficult to understand, but far, far worse, we’re repeating the calculation for total order value. This is a bug waiting to happen. Now if we update the calculation for total order value we have to know all the queries that need to be updated. We can imagine if we string just a few more of these calculations together how unwieldy the SQL would become. SQL just isn’t expressive enough for us to build a system this way, which is why we are motivated to move these business calculations into the middle tier, or application layer, instead.
The Split Brain Problem
So what’s wrong with moving our business logic into our application layer? We’ve been doing that for decades. First, the ontology of our business is now distributed between our database and our application layer, with neither place having the complete picture. For example, we can’t tell just by looking at the database schema exactly how we should calculate the total order price. And we can’t tell by looking at our application layer all the database constraints. We refer to this as the “split brain” problem.
What happens in the future when we realize this schema doesn’t represent our actual business? Why do we need the unit_price AND the discount percentage on the order? Shouldn’t unit_price be associated with the product (and a point in time) and not the order? With the current schema we have no historical data of product pricing. If we want to fix that, we’re now updating our database schema, our application layer’s mapping to our database schema, and how the application layer implements the business rules.
Another problem is that while in this case calculating the total price on every request probably isn’t very expensive, what if the feature was actually querying the total revenue for a product across all orders? If we’re an online retailer there are going to be millions of orders. We can’t just query them all out and sum them up. Even querying the total per product in SQL might be prohibitively expensive to do every time we request it.
The RAI Way
We’ve asserted that the traditional approach to business application development is complex because of the distribution of code, business logic, and data across multiple layers. Now let’s look at how we might do this differently using RAI’s RKGS.
The first thing we’d do differently is that we would add total order price to the order schema like so:

Now anyone who looks at the orders schema in the knowledge graph will be able to see the total price of an order. To consumers of this model, there is no difference whether this is a calculation or it’s just data. They query it the same way. In other words, the knowledge of how order prices are calculated is kept with the rest of the ontology and it’s available for use by anyone. Like say, for use in the calculation of total customer lifetime value:

Here you’ll notice we don’t repeat the definition of orders:total_value. If we were to redefine how to calculate orders:total_value, we don’t have to update this or any other rule. Compare this to the SQL version from before where we were embedding the definition of the order total_value everywhere it was used.
As we continue to make changes to the ontology of our business, such as keeping historical prices for products, all the knowledge about products, orders, and prices is kept in one place and can be easily updated.
With this computation performed in the database, we no longer need any application logic in our middle tier, or maybe we don’t even need a middle tier at all.
The Bottom Line
Business applications are traditionally complicated to understand and maintain because business logic tends to be scattered in separate tiers of growing code bases, while schema becomes rigid and brittle. The end result is that business logic dissolves in a soup of disparate application code.
Even for problems that are not thought of as traditional graph problems, RAI’s approach has huge benefits. By capturing the complete business ontology and business knowledge in one place, developers can deliver dramatically simpler applications in far less time.
Related Posts

Rel: Live Programming and Self-Modifying Models
Introducing Rel semantics for self modification.

Automatically Close Unused Databases
Up until now, database instances that you opened during your work would stick around in the engine’s memory, leading to potentially unbounded memory usage.